Geostatistical Analyst. Análisis geoestadístico con ArcGIS parte 3
Con Geostatistical Analyst es posible explorar la variabilidad de datos, examinar tendencias globales e investigar la autocorrelación y la correlación entre los datos, de igual forma se pueden crear predicciones y calcular errores de predicciones.
Lo primero que se tiene que hacer para iniciar un análisis geoestadístico con Arcgis es el análisis exploratorio de los datos, lo cual hemos visto en dos artículos anteriores y por último el análisis estructural de los datos.
1. Análisis Exploratorio de los datos (ver artículo)
Paso 1
Lo primero que se debe hacer es crear un shape de puntos a partir de datos de coordenadas geográficas o planas.
En este caso utilizaré, el shape de puntos donde se tiene datos del monitoreo de niveles del acuífero del golfo de Urabá, el cual se denomina Niveles.shp.
Paso 2
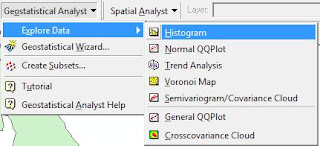
Una vez creado o agregado el shape en Arcmap, damos clic en Geostatistical Analyst, seguido de Explore Data y finalmente en Histogram, tal como se muestra en la figura.
Aparece la siguiente ventana…
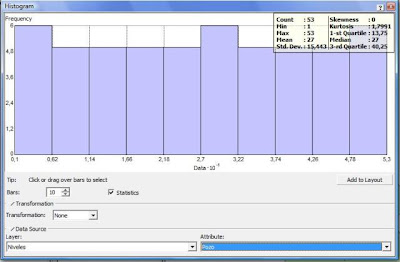
En la parte inferior de la ventana,
Bars: Permite elegir el número de intervalos, la herramienta automáticamente calcula la longitud de cada intervalo.
Transformation: Permite realizar una transformación logarítmica a los datos en caso de que estos no sigan una distribución normal (tal como fue explicado aquí).
Layer: Aquí aparece el nombre del Shape, el cual es Niveles, cuando hay varios shpe agregados en Arcmap la herramienta elige el primero de la lista.
Attribute: Aquí aparece por defecto el primer campo que tenemos en la tabla de atributos de nuestro shape… en este caso es el campo pozos. Automáticamente la herramienta calcula los parámetros geoestadísticos que se muestran en la parte superior.
Paso 3
Lo que sigue es seleccionar el atributo con el cual queremos hacer el análisis geoestadístico, en este caso es el nivel piezométrico, para ello damos clic en la pestaña que está debajo del Attribute y seleccionamos el campo “NP” (nivel piezométrico).
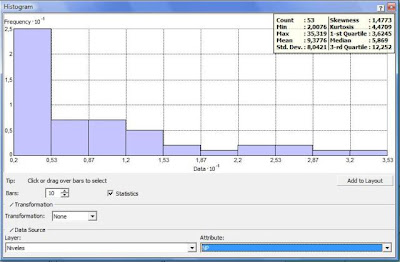
Se observa que inmediatamente cambia la grafica y recalcula los valores de los parámetros estadísticos mostrados en la parte superior, los cuales son los siguientes:
Count (numero de datos): 53
Min (dato menor): 2.0076
Max (dato mayor): 35.319
Mean (Media): 9.3776
Std Dev (Desviación estándar): 8.0421
Skewness (Coeficiente de sesgo o asimetría): 1.4773
Kurtosis (curtosis): 4.4709
Median (Mediana): 5.69
Aquí, la moda se calcula como la marca de clase del intervalo con mayor frecuencia…
Moda = (0.2+0.53)/2 = 0.365.
El coeficiente de variación se calcula como: CV=S/media*100
CV=8.0421/9.3776*100 = 85.7%
A estos parámetros le aplicamos las condiciones necesarias para verificar si los datos siguen la distribución normal. Vemos que la media, la moda y la mediana son diferentes y su diferencia es mayor a uno, el coeficiente de sesgo es mayor a 1, por lo cual es necesario realizar una transformación de los datos, de acuerdo a la literatura y lo hablado anteriormente se recomienda una transformación logarítmica…pero no los preocupemos estos lo hace ArcGis, simplemente en la pestaña Transformation seleccionamos “Log”. En la pestaña Bars colocamos 8 intervalos. El resultado es el siguiente.
Observamos nuevamente los parámetros…
Count (numero de datos): 53
Min (dato menor): 0.69694
Max (dato mayor): 3.5644
Mean (Media): 1.9248
Std Dev (Desviación estándar): 0.78698
Skewness (Coeficiente de sesgo o asimetría): 0.33899
Kurtosis (curtosis): 2.0591
Median (Mediana): 1.7697
El coeficiente de variación se calcula como: CV=S/media*100
CV=0.78698/1.9248*100 = 40.88%
El coeficiente de variación mejoró y es igual a 40.88%, por lo cual no hay problema con los valores extremos de los datos.
De lo anterior se concluye que la media y la mediana son similares, su diferencia es menor a 1 y el coeficiente de sesgo está entre 0 y 0.5, por lo cual la distribución de los datos se acepta como normal…se sigue con el análisis geoestadístico.
Paso 4
Después de haber analizado los parámetros estadísticos y concluir que la distribución de los datos se puede tomar como normal, cerramos la ventana del Histogram y volvemos a dar clic en Geostatistical Analyst, seguido de Explore Data y finalmente en Trend Analysis, tal como se muestra en la figura.
Se abre la siguiente ventana…
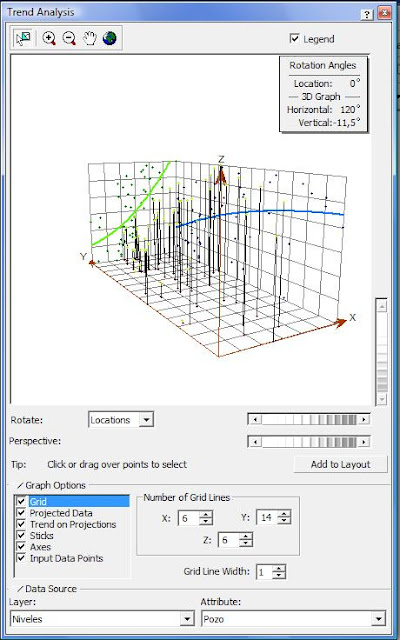
Esta ventana nos ayuda a ver qué tendencia siguen los datos para que luego en el análisis estrutural le indiquemos a la herramienta que sea removida. En Graph options, damos clic en Projected Data, Sticks, Input Data Points para que desaparezcan de la gráfica… el resultado debe ser el siguiente.
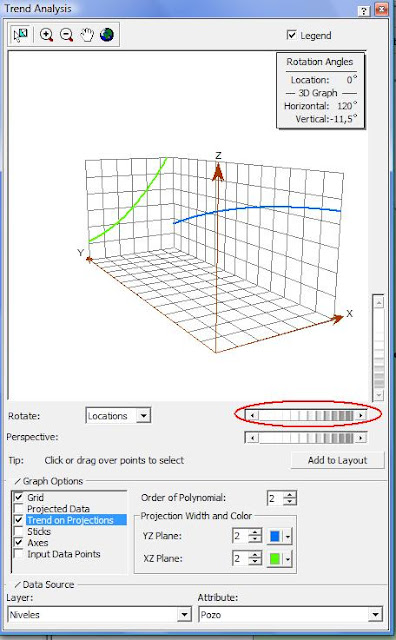
Es importante analizar si los datos manifiestan tendencias direccionales que permitan establecer correlaciones en esas direcciones, y formular modelos de comportamiento. La tendencia más fuerte se tendrá sobre aquella dirección en la que la línea de tendencia es más gruesa; para nuestro ejemplo se ve claramente una fuerte tendencia en la dirección este-oeste (línea verde) y una débil tendencia en la dirección norte-sur (línea azul).
Con la barra de desplazamiento resaltada en rojo en la figura anterior se empiezan a desplazar las líneas de tendencias (verde y azul de la misma figura)… y se observa si estas siguen una línea recta, en caso tal la tendencia es lineal; una curva con una concavidad, la tendencia es cuadrática o si es una línea con más de una concavidad, la tendencia será de orden 3.
Como conclusión del análisis exploratorio y que se debe tener en cuenta durante la realización del análisis estructural de los datos, tenemos:
- Los datos originales no siguen una distribución normal, por lo tanto se aplica una transformación logarítmica.
- Es necesario remover una tendencia de segundo orden
2. Análisis estructural de los datos
Paso 5
Una vez identificada la tendencia de los datos, el siguiente paso es el análisis estructural y realización del modelo geoestadístico con los datos…para ello damos clic en Geostatistical Analyst, seguido de Geostatistical Winzard, aparece la una ventana donde debemos rellanar la siguiente información.
Medthod: Se debe seleccionar el método con el cual se quieren analizar los datos, en este caso es Kriging
Input data: el shape al cual se le debe aplicar el análisis geoestadístico en este caso es Niveles.
Attibute: El campo con el que se quiere realizar el análisis geoestadístico. En esta caso es el nivel piezométrico (NP).
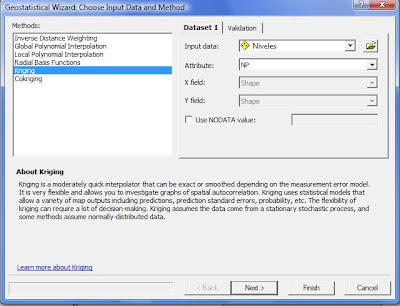
Damos clic en el botó Next>. Aparece la siguiente ventana, donde rellenamos la siguiente información.
- En Geostatistical methods, se selecciona Ordinary Kriging-Prediction Map.
- En Transformation, se selecciona Log, pues ya habíamos concluido que es necesario realizar transformación logarítmica.
- En Order of trend removal, se selecciona la opción Second, pues habíamos visto que los datos siguen una tendencia de segundo orden.
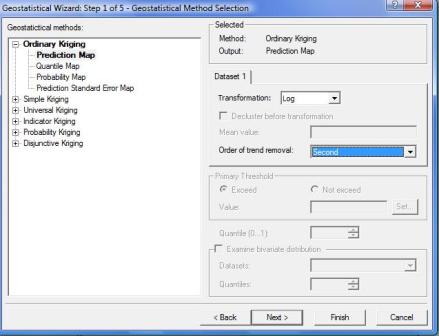
Damos clic en Next>, aparece una ventana que permite concluir si los datos presentan anisotropía direccional o no la presentan. Si en la grafica aparece un círculo, no hay anisotropía direccional y si aparece otra cosa como la de la figura, se concluye que existe anisotropía direccional la cual se debe tener presente, ya que en la ventana siguiente se le deberá indicar a la herramienta este parámetro.
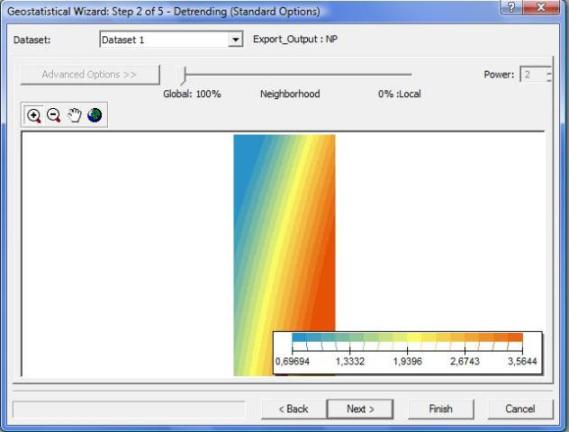
Damos clic en Next>, aparece la siguiente ventana.
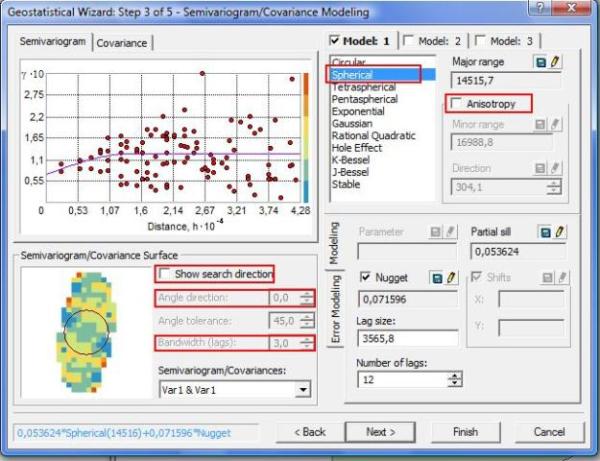
En la ventana anterior rellenamos la siguiente información
1. Model: 1. Aquí debemos elegir el modelo geoestadístico que deseemos usar para modelar los datos; para el caso del ejemplo, elegiremos el modelo Spherical.
2. En el paso anterior concluimos que hay anisotropía estructural, por lo tanto, debemos seleccionar Anisotropy.
3. Damos clic en Show search Direction, se habilitarán inmediatamente las opciones de más abajo, las cuales son Angle direction y Bandwidth (lags).
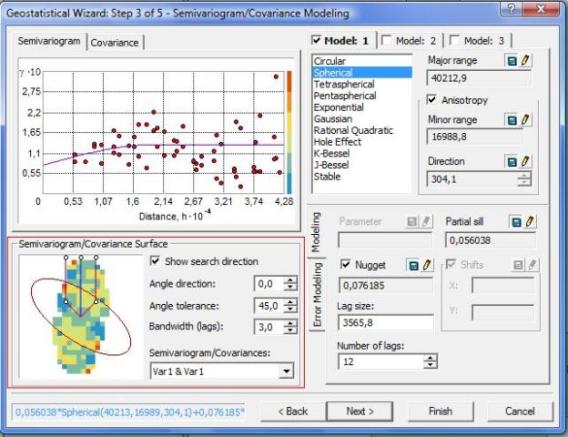
En la grafica anterior vemos que fueron habilitadas Angle direction y Bandwidth (lags), para seguir se procede de la siguiente forma.
Angle direction: Debemos cambiar el Angulo hasta que las líneas que se muestran a la izquierda de la figura coincidan con la dirección de la elipse en su parte superior.
Bandwidth (lags): una vez realizado el paso anterior, los puntos o parte inferior de las líneas deben cortar a la elipse, para ello se aumenta o disminuye el valor de Bandwidth.
…lo dicho anteriormente se resumen en la siguiente imagen.
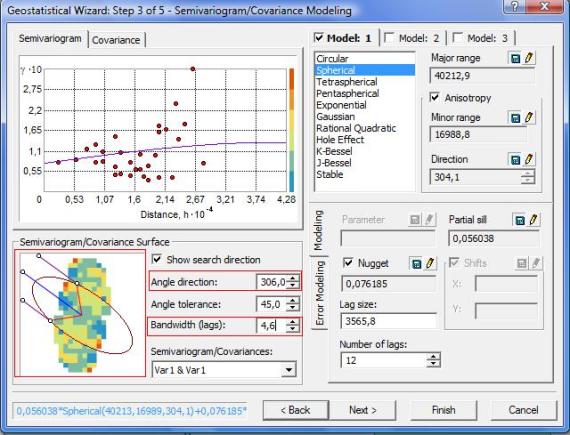
Después de dar clic en Next>, se muestra la siguiente ventana.
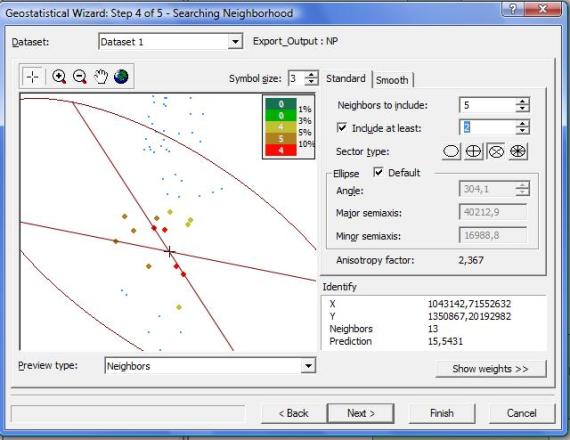
Volvemos a dar clic en Next>, en la siguiente ventana se muestra:
- Un recalculo de los datos en comparación con los valores medidos para verificar obtenido.
- Cálculo de los errores:
Root-Mean-Square: 3.774
Average Standard Error: 4.361
Mean Standardized: -0.04804
Root-Mean-Square Standardized: 0.9609
- Un gráfico de comparación de datos medidos y datos calculados, en la que se puede ver que los datos que más se alejan de la línea, son los que mayores errores presentan en su predicción.
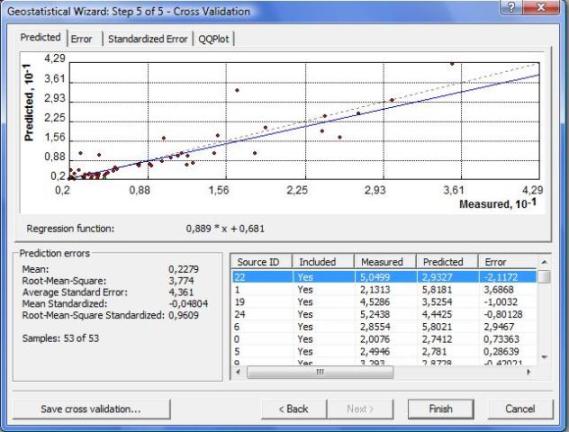
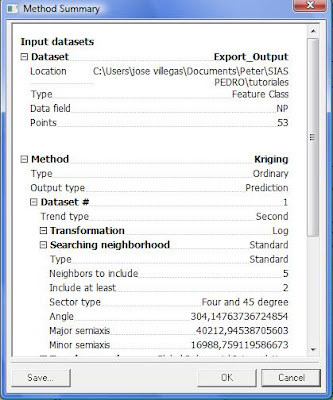
Damos clic en finish y aparece un resumen del método utilizado.
Damos clic en Ok y aparece el mapa de predicción de niveles piezométrico a partir del método geoestadístico Kriging esférico.
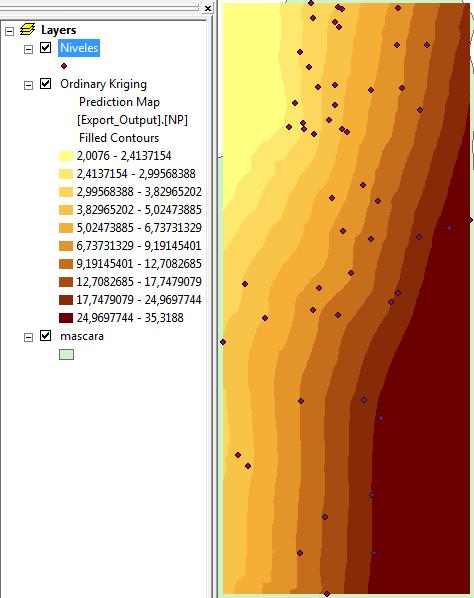
Pero aun no se termina …la ventajas de los métodos geoestadísticos es que nos permite realizar un mapa de errores. Para ello en el panel del navegador, damos clic derecho sobre el mapa creado y elegimos la opción Create Prediction Estándar error Map.
El resultado es el siguiente.
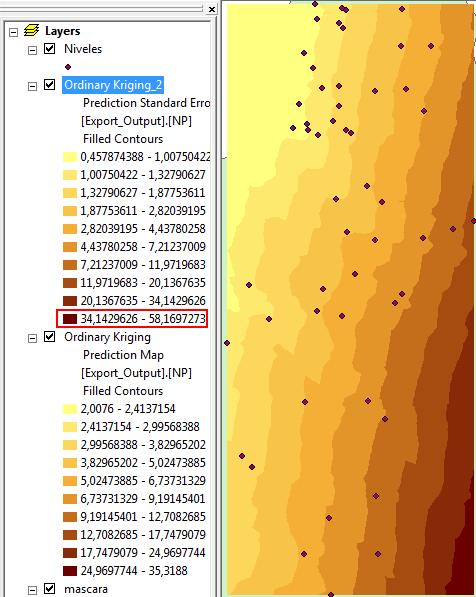
En la figura anterior observamos que el máximo error es del 58.16%, el cual es muy alto. La confiabilidad del modelo se calcula como 100 menos el error máximo, para el ejemplo: confiabilidad = 100-58.16 = 41.84%. Para aceptar un modelo geoestadístico es necesario tener una confiabilidad superior al 90%, por lo tanto se concluye que es necesario mejorar la densidad de las medidas.
En la gráfica también se observa que los errores mayores en la predicción se producen donde existe menos información. Para el caso del monitoreo de niveles de un acuífero esto es indicativo que en estos sitios se deben perforar piezómetros o pozos de monitoreo con el fin de optimizar la red existente.
Para seleccionar el modelo que mejor modela nuestros datos, es necesario aplicarles cada uno de ellos y escoger el que presente menor Root-Mean-Square, menor Average Standard Error, Root-Mean-Square Standardized más cercano a uno y mayor porcentaje de confiabilidad.
Como resumen del modelo aplicado tenemos lo siguiente:
| Parámetro | Valor |
| Root-Mean-Square | 3.774 |
| Average Standard Error | 4.361 |
| Root-Mean-Square Standardized | 0.9609 |
| Confiabilidad | 41.84 |
Existen otros conceptos que son muy importantes, pero de los cuales no fue posible mencionar en este artículo: efecto pepita, efecto pepita puro, discontinuidad en el origen, meseta, anisotropía estructural, anisotropía direccional, variograma y partial sill, entre otros. Para profundizar en este tema recomiendo revisar la siguiente bibliografía.
Webster, Richard. Oliver Margaret. 2001. Geostatistics for environmental scientists. Great Britain. John Wiley & Sons Inc.
Sampe Javier y Jesús carrera. 1990. Geoestadistica, aplicaciones a la hidrogeología subterránea. Centro Internacional de métodos nuéricos en Ingeniería. Barcelona
http://cg.ensmp.fr/bibliotheque/public/MATHERON_Ouvrage_00537.pdf
http://www.fcaglp.unlp.edu.ar/~jcu/estadistica/Nociones%20de%20geoestad%EDstica.pdf