Análisis geoestadístico con ArcGIS parte 2. Análisis exploratorio de los datos
Según Matheron (1992), la Geoestadística es la aplicación de la teoría de las variables regionalizadas a la estimación de los depósitos. A su vez una variable regionalizada, es una variable distribuida en el espacio de forma que presenta una estructura espacial de correlación. En fin cuando hablemos de Geoestadística se debe pensar en la variable y su relación espacial.
Ejemplo de variables regionalizadas en hidrogeología son la trasmisividad y conductividad hidráulica, la porosidad y el nivel piezométrico; a este último hacemos referencia en el presente artículo.
La mayoría de los métodos geoestadísticos sólo son óptimos si la variable de estudio sigue una distribución normal. Recordemos que la distribución normal tiene las siguientes propiedades:
- Tiene una única moda, que coincide con su media y su mediana.
- La curva normal es asintótica al eje de abscisas.
- Es simétrica con respecto a su media. Según esto, para este tipo de variables existe una probabilidad de un 50% de observar un dato mayor que la media, y un 50% de observar un dato menor.
- Cuanto mayor sea la desviación estándar, más se dispersarán los datos en torno a la media y la curva será más plana. Un valor pequeño de este parámetro indica, por tanto, una gran probabilidad de obtener datos cercanos al valor medio de la distribución.
- El coeficiente de sesgo es igual a cero (0).
- La curtosis es igual a cero (0).
Para determinar si la variable sigue una distribución se deben aplicar alguna de las pruebas de normalidad como Prueba X², Kolmogorov, cálculo del coeficiente de asimetría, curtosis, mediana, mediana y la moda y su comparación de con los de la distribución normal.
Si a través de estas pruebas se concluye que la variable puede ser aceptada o se aproxima a una distribución normal, el problema se simplifica y se puede continuar con el análisis geoestadístico; de lo contrario, es necesario realizar una transformación de los datos que puede ser de raíz cuadrada o logarítmica (Carrera, 1990) y hacer nuevamente las verificaciones.
Este es un tema extenso y la idea de estos artículos es hacerlos algo prácticos, por ello al final dejaré bibliografía a la cual se puede consultar.
Para resumir, los pasos a seguir en el análisis exploratorio de los datos son los siguientes.
- Organizar los datos de menor a mayor.
- Calcular la tabla de frecuencia.
- Realizar el histograma de frecuencias.
- Calcular los parámetros geoestadístico.
- Verificación de la normalidad con respecto a la media, moda y mediana.
- Verificación de la normalidad con respecto a la asimetría horizontal (coeficiente de sesgo).
- Verificación de la normalidad con respecto al coeficiente de variación.
- Realización de la transformación de los datos, si es necesario.
- Recalculo de los parámetros estadísticos y comparación para verificar la normalidad de los datos.
Los pasos 1 al 4 fueron realizados en el tutorial “Módulo de Geostadística Analyst con ArcGIS parte 1. Estadística descriptiva”, aquí se continuará con los pasos siguientes
Se continua con el ejemplo de los datos del monitoreo de niveles piezométricos que se muestran en la siguiente tabla.
Pozo | X | Y | NP |
1 | 1.038.638 | 1.368.620 | 2,0076 |
2 | 1.034.835 | 1.344.198 | 2,1313 |
3 | 1.039.637 | 1.368.963 | 2,2000 |
4 | 1.039.628 | 1.368.960 | 2,2100 |
5 | 1.042.236 | 1.377.584 | 2,4449 |
6 | 1.039.030 | 1.370.440 | 2,4946 |
7 | 1.036.835 | 1.354.454 | 2,8554 |
8 | 1.043.217 | 1.357.777 | 2,9876 |
9 | 1.040.082 | 1.373.095 | 3,2347 |
10 | 1.039.392 | 1.374.231 | 3,2930 |
11 | 1.040.434 | 1.368.119 | 3,3317 |
12 | 1.039.720 | 1.368.500 | 3,3506 |
13 | 1.042.060 | 1.376.470 | 3,4291 |
14 | 1.041.545 | 1.369.212 | 3,6896 |
15 | 1.042.045 | 1.371.752 | 3,7990 |
16 | 1.040.269 | 1.377.908 | 3,9651 |
17 | 1.040.731 | 1.371.643 | 3,9980 |
18 | 1.042.360 | 1.376.070 | 4,2921 |
19 | 1.040.390 | 1.376.776 | 4,4900 |
20 | 1.035.335 | 1.356.941 | 4,5286 |
21 | 1.047.035 | 1.371.548 | 4,6227 |
22 | 1.042.020 | 1.370.310 | 4,6637 |
23 | 1.033.716 | 1.352.675 | 5,0499 |
24 | 1.042.570 | 1.377.470 | 5,1009 |
25 | 1.035.564 | 1.343.433 | 5,2438 |
26 | 1.042.520 | 1.368.530 | 5,3826 |
27 | 1.042.932 | 1.368.255 | 5,8690 |
28 | 1.044.694 | 1.371.405 | 6,0000 |
29 | 1.041.841 | 1.363.397 | 6,1496 |
30 | 1.040.838 | 1.356.677 | 8,0054 |
31 | 1.044.135 | 1.364.301 | 8,0724 |
32 | 1.046.740 | 1.377.526 | 8,0827 |
33 | 1.046.626 | 1.374.772 | 9,0188 |
34 | 1.042.604 | 1.360.903 | 9,2078 |
35 | 1.039.466 | 1.348.279 | 10,1156 |
36 | 1.041.429 | 1.333.870 | 10,2553 |
37 | 1.045.207 | 1.363.183 | 10,8373 |
38 | 1.044.733 | 1.360.337 | 11,5066 |
39 | 1.048.893 | 1.374.744 | 11,8241 |
40 | 1.040.383 | 1.355.006 | 12,2268 |
41 | 1.042.263 | 1.354.636 | 12,3280 |
42 | 1.039.411 | 1.336.953 | 12,8004 |
43 | 1.048.342 | 1.369.941 | 14,6244 |
44 | 1.046.214 | 1.355.644 | 14,9301 |
45 | 1.044.935 | 1.336.931 | 16,6351 |
46 | 1.041.256 | 1.339.628 | 18,1630 |
47 | 1.048.313 | 1.360.466 | 19,1410 |
48 | 1.044.224 | 1.348.328 | 24,0632 |
49 | 1.044.765 | 1.341.254 | 24,2354 |
50 | 1.046.735 | 1.356.327 | 25,5698 |
51 | 1.045.454 | 1.346.959 | 27,1534 |
52 | 1.050.523 | 1.361.111 | 30,0800 |
53 | 1.052.106 | 1.361.728 | 35,3188 |
Los parámetros estadísticos calculados anteriormente se resumen en la siguiente tabla.
Parámetro | Datos no agrupados | Observaciones |
Media | 9.3776 |
|
Mediana | 5.869 |
|
Moda | 4.378 | Se tomó la moda calculada a través de la ecuación datos agrupados. |
Desviación estándar | 8.0421 |
|
Varianza | 64.675 |
|
Coeficiente de Variación | 85.8% |
|
Curtosis | 1.38 |
|
Sesgo o asimetría | 1.46 |
|
5. Verificación de la normalidad con respecto a la media, moda y mediana.
Para que la distribución sea normal o se aproxime, la media, la moda y la mediana deben ser similares, se acepta una diferencia de una unidad entre ella.
Para el ejemplo de estudio tenemos.
Media = 9.3776
Mediana = 5.869
Moda = 4.378
Se observa la media, la mediana y la moda son diferentes, por lo cual los datos no cumplen el criterio de verificación con respecto a estos parámetros.
6. Verificación de la normalidad con respecto a la asimetría horizontal (coeficiente de sesgo).
Como el coeficiente de sesgo permite verificar la normalidad de los datos, en caso de existir asimetría horizontal, es decir los datos no se ajustan a una distribución normal, Wester-Oliver proponen evaluar lo siguiente.
- 0<|CS|<0.5, se acepta la función de distribución de probabilidad como normal, se puede aplicar el método geoestadístico a los datos.
- 0.5<|CS|<1, es necesario realizar una transformación de datos (normalización) de tipo raíz cuadrada.
- |CS|>1, es necesario hacer una transformación de tipo logarítmico (ln o log)
En nuestro caso CS = 1.46, valor mayor que 1, por lo tanto es necesario aplicar una transformación de tipo logarítmico a los datos.
7. Verificación de la normalidad con respecto al coeficiente de variación.
Tanto la función de distribución de los datos como la varianza son funciones de la media la cual es altamente sensible a los valores extremos. En consecuencia se debe tener conocimiento de la afectación de estos valores extremos sobre la media, para ello se calcula el coeficiente de variación. En todo caso se debe verificar lo siguiente.
- Si CV < 100, no hay problema con los valores extremos de los datos
- Si 100<CV<=200, Los efectos causados por los valores extremos de los datos son tolerables
- Si CV>200, se tiene problemas severos con los valores extremos de los datos.
Esto es importante, pues en caso de que los valores extremos de los datos afecten a la muestra o a la distribución de los mismos, se deberá analizar si es conveniente eliminarlos en caso que obedezcan a un error en la medición o hacer una transformación de los datos para reducir su influencia en la muestra.
En nuestro caso CV = 85.8 < 100, lo cual indica que no hay problemas con valores extremos.
En resumen, la función de distribución de los datos no se asemeja a una distribución normal dado que la media, la mediana y la moda son diferentes y además el CS>1. De acuerdo a los cálculos anteriores, es necesario realizar una transformación logarítmica (la cual consiste en tomar el dato y sacarle el logaritmo ya sea en base 10 o logaritmo natural), una vez realizada la transformación se vuelven a calcular todos los parámetros para realizar las respectivas verificaciones.
8. Realización de la transformación de los datos, si es necesario.
Transformación de los datos (ln).
Pozo | X | Y | NP | ln |
1 | 1.038.638 | 1.368.620 | 2,0076 | 0,697 |
2 | 1.034.835 | 1.344.198 | 2,1313 | 0,757 |
3 | 1.039.637 | 1.368.963 | 2,2000 | 0,788 |
4 | 1.039.628 | 1.368.960 | 2,2100 | 0,793 |
5 | 1.042.236 | 1.377.584 | 2,4449 | 0,894 |
6 | 1.039.030 | 1.370.440 | 2,4946 | 0,914 |
7 | 1.036.835 | 1.354.454 | 2,8554 | 1,049 |
8 | 1.043.217 | 1.357.777 | 2,9876 | 1,094 |
9 | 1.040.082 | 1.373.095 | 3,2347 | 1,174 |
10 | 1.039.392 | 1.374.231 | 3,2930 | 1,192 |
11 | 1.040.434 | 1.368.119 | 3,3317 | 1,203 |
12 | 1.039.720 | 1.368.500 | 3,3506 | 1,209 |
13 | 1.042.060 | 1.376.470 | 3,4291 | 1,232 |
14 | 1.041.545 | 1.369.212 | 3,6896 | 1,306 |
15 | 1.042.045 | 1.371.752 | 3,7990 | 1,335 |
16 | 1.040.269 | 1.377.908 | 3,9651 | 1,378 |
17 | 1.040.731 | 1.371.643 | 3,9980 | 1,386 |
18 | 1.042.360 | 1.376.070 | 4,2921 | 1,457 |
19 | 1.040.390 | 1.376.776 | 4,4900 | 1,502 |
20 | 1.035.335 | 1.356.941 | 4,5286 | 1,510 |
21 | 1.047.035 | 1.371.548 | 4,6227 | 1,531 |
22 | 1.042.020 | 1.370.310 | 4,6637 | 1,540 |
23 | 1.033.716 | 1.352.675 | 5,0499 | 1,619 |
24 | 1.042.570 | 1.377.470 | 5,1009 | 1,629 |
25 | 1.035.564 | 1.343.433 | 5,2438 | 1,657 |
26 | 1.042.520 | 1.368.530 | 5,3826 | 1,683 |
27 | 1.042.932 | 1.368.255 | 5,8690 | 1,770 |
28 | 1.044.694 | 1.371.405 | 6,0000 | 1,792 |
29 | 1.041.841 | 1.363.397 | 6,1496 | 1,816 |
30 | 1.040.838 | 1.356.677 | 8,0054 | 2,080 |
31 | 1.044.135 | 1.364.301 | 8,0724 | 2,088 |
32 | 1.046.740 | 1.377.526 | 8,0827 | 2,090 |
33 | 1.046.626 | 1.374.772 | 9,0188 | 2,199 |
34 | 1.042.604 | 1.360.903 | 9,2078 | 2,220 |
35 | 1.039.466 | 1.348.279 | 10,1156 | 2,314 |
36 | 1.041.429 | 1.333.870 | 10,2553 | 2,328 |
37 | 1.045.207 | 1.363.183 | 10,8373 | 2,383 |
38 | 1.044.733 | 1.360.337 | 11,5066 | 2,443 |
39 | 1.048.893 | 1.374.744 | 11,8241 | 2,470 |
40 | 1.040.383 | 1.355.006 | 12,2268 | 2,504 |
41 | 1.042.263 | 1.354.636 | 12,3280 | 2,512 |
42 | 1.039.411 | 1.336.953 | 12,8004 | 2,549 |
43 | 1.048.342 | 1.369.941 | 14,6244 | 2,683 |
44 | 1.046.214 | 1.355.644 | 14,9301 | 2,703 |
45 | 1.044.935 | 1.336.931 | 16,6351 | 2,812 |
46 | 1.041.256 | 1.339.628 | 18,1630 | 2,899 |
47 | 1.048.313 | 1.360.466 | 19,1410 | 2,952 |
48 | 1.044.224 | 1.348.328 | 24,0632 | 3,181 |
49 | 1.044.765 | 1.341.254 | 24,2354 | 3,188 |
50 | 1.046.735 | 1.356.327 | 25,5698 | 3,241 |
51 | 1.045.454 | 1.346.959 | 27,1534 | 3,302 |
52 | 1.050.523 | 1.361.111 | 30,0800 | 3,404 |
53 | 1.052.106 | 1.361.728 | 35,3188 | 3,564 |
9. Recalculo de los parámetros estadísticos y comparación para verificar la normalidad de los datos.
a. Organizar los datos de menor a mayor.
Ya están organizados en la tabla anterior
b. Calcular la tabla de frecuencia.

No | Intervalo | Marca de clase | frecuencia absoluta | frecuencia absoluta acumulada | frecuencia relativa | frecuencia relativa acumulada | |
1 | 0,6969 | - 1,0569 | 0,88 | 7 | 7 | 0,13 | 0,13 |
2 | 1,0569 | - 1,4153 | 1,24 | 10 | 17 | 0,19 | 0,32 |
3 | 1,4153 | - 1,7737 | 1,59 | 10 | 27 | 0,19 | 0,51 |
4 | 1,7737 | - 2,1321 | 1,95 | 5 | 32 | 0,09 | 0,60 |
5 | 2,1321 | - 2,4905 | 2,31 | 7 | 39 | 0,13 | 0,74 |
6 | 2,4905 | - 2,8489 | 2,67 | 6 | 45 | 0,11 | 0,85 |
7 | 2,8489 | - 3,2073 | 3,03 | 4 | 49 | 0,08 | 0,92 |
8 | 3,2073 | - 3,5657 | 3,39 | 4 | 53 | 0,08 | 1,00 |
c. Realizar el histograma de frecuencias

d. Calcular los parámetros geoestadístico.
Los parámetros estadísticos se realizarán por la metodología de datos no agrupados a excepción de la moda, para ello se utilizará Excel.
Pozo | NP | ln | Media | (xi-media)2 | (xi-media)4 | (xi-media)³ |
1 | 2,0076 | 0,697 | 1,92 | 1,508 | 2,273 | -1,851 |
2 | 2,1313 | 0,757 | 1,92 | 1,364 | 1,862 | -1,594 |
3 | 2,2000 | 0,788 | 1,92 | 1,291 | 1,668 | -1,468 |
4 | 2,2100 | 0,793 | 1,92 | 1,281 | 1,641 | -1,450 |
5 | 2,4449 | 0,894 | 1,92 | 1,063 | 1,129 | -1,095 |
6 | 2,4946 | 0,914 | 1,92 | 1,022 | 1,044 | -1,033 |
7 | 2,8554 | 1,049 | 1,92 | 0,767 | 0,588 | -0,671 |
8 | 2,9876 | 1,094 | 1,92 | 0,690 | 0,475 | -0,573 |
9 | 3,2347 | 1,174 | 1,92 | 0,564 | 0,318 | -0,423 |
10 | 3,2930 | 1,192 | 1,92 | 0,537 | 0,289 | -0,394 |
11 | 3,3317 | 1,203 | 1,92 | 0,520 | 0,271 | -0,375 |
12 | 3,3506 | 1,209 | 1,92 | 0,512 | 0,262 | -0,367 |
13 | 3,4291 | 1,232 | 1,92 | 0,480 | 0,230 | -0,332 |
14 | 3,6896 | 1,306 | 1,92 | 0,384 | 0,147 | -0,238 |
15 | 3,7990 | 1,335 | 1,92 | 0,348 | 0,121 | -0,205 |
16 | 3,9651 | 1,378 | 1,92 | 0,300 | 0,090 | -0,164 |
17 | 3,9980 | 1,386 | 1,92 | 0,291 | 0,084 | -0,157 |
18 | 4,2921 | 1,457 | 1,92 | 0,219 | 0,048 | -0,103 |
19 | 4,4900 | 1,502 | 1,92 | 0,179 | 0,032 | -0,076 |
20 | 4,5286 | 1,510 | 1,92 | 0,172 | 0,029 | -0,071 |
21 | 4,6227 | 1,531 | 1,92 | 0,155 | 0,024 | -0,061 |
22 | 4,6637 | 1,540 | 1,92 | 0,148 | 0,022 | -0,057 |
23 | 5,0499 | 1,619 | 1,92 | 0,093 | 0,009 | -0,029 |
24 | 5,1009 | 1,629 | 1,92 | 0,087 | 0,008 | -0,026 |
25 | 5,2438 | 1,657 | 1,92 | 0,072 | 0,005 | -0,019 |
26 | 5,3826 | 1,683 | 1,92 | 0,058 | 0,003 | -0,014 |
27 | 5,8690 | 1,770 | 1,92 | 0,024 | 0,001 | -0,004 |
28 | 6,0000 | 1,792 | 1,92 | 0,018 | 0,000 | -0,002 |
29 | 6,1496 | 1,816 | 1,92 | 0,012 | 0,000 | -0,001 |
30 | 8,0054 | 2,080 | 1,92 | 0,024 | 0,001 | 0,004 |
31 | 8,0724 | 2,088 | 1,92 | 0,027 | 0,001 | 0,004 |
32 | 8,0827 | 2,090 | 1,92 | 0,027 | 0,001 | 0,004 |
33 | 9,0188 | 2,199 | 1,92 | 0,075 | 0,006 | 0,021 |
34 | 9,2078 | 2,220 | 1,92 | 0,087 | 0,008 | 0,026 |
35 | 10,1156 | 2,314 | 1,92 | 0,152 | 0,023 | 0,059 |
36 | 10,2553 | 2,328 | 1,92 | 0,162 | 0,026 | 0,065 |
37 | 10,8373 | 2,383 | 1,92 | 0,210 | 0,044 | 0,096 |
38 | 11,5066 | 2,443 | 1,92 | 0,268 | 0,072 | 0,139 |
39 | 11,8241 | 2,470 | 1,92 | 0,297 | 0,088 | 0,162 |
40 | 12,2268 | 2,504 | 1,92 | 0,335 | 0,112 | 0,194 |
41 | 12,3280 | 2,512 | 1,92 | 0,345 | 0,119 | 0,202 |
42 | 12,8004 | 2,549 | 1,92 | 0,390 | 0,152 | 0,244 |
43 | 14,6244 | 2,683 | 1,92 | 0,574 | 0,330 | 0,435 |
44 | 14,9301 | 2,703 | 1,92 | 0,606 | 0,367 | 0,472 |
45 | 16,6351 | 2,812 | 1,92 | 0,786 | 0,618 | 0,697 |
46 | 18,1630 | 2,899 | 1,92 | 0,950 | 0,902 | 0,926 |
47 | 19,1410 | 2,952 | 1,92 | 1,055 | 1,112 | 1,083 |
48 | 24,0632 | 3,181 | 1,92 | 1,577 | 2,487 | 1,981 |
49 | 24,2354 | 3,188 | 1,92 | 1,595 | 2,544 | 2,015 |
50 | 25,5698 | 3,241 | 1,92 | 1,733 | 3,004 | 2,282 |
51 | 27,1534 | 3,302 | 1,92 | 1,895 | 3,592 | 2,609 |
52 | 30,0800 | 3,404 | 1,92 | 2,187 | 4,785 | 3,235 |
53 | 35,3188 | 3,564 | 1,92 | 2,688 | 7,226 | 4,407 |
suma | 102,02 | 32,205 | 40,295 | 8,510 |
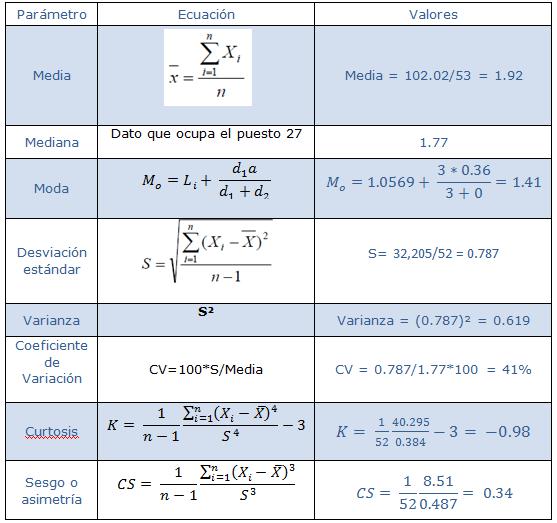
e. Verificación de la normalidad con respecto a la media, moda y mediana.
Media = 1.92
Mediana = 1.77
Moda = 1.41
La diferencia entre la media, la mediana y la moda es menor que 1, por lo tanto la distribución de los datos cumple con esta condición.
f. Verificación de la normalidad con respecto a la asimetría horizontal (coeficiente de sesgo).
CS = 0.34 se cumple que 0<|CS|<0.5.
g. Verificación de la normalidad con respecto al coeficiente de variación.
CV = 41%, se cumple que CV<100
Por tanto la distribución de los datos se puede aceptar como normal, dado que la moda, la mediana y la media son similares; CS está entre 0 y 0.5 y CV<100. Por ello se puede continuar con el análisis geoestadístico.
La tercera parte de esta trilogía que corresponde a la herramienta Geostadistical Analyst la puedes consultar aquí.